
Related articles:
- GPU Computing: GeForce and Radeon OpenCL Test (Part 2)
- GPU Computing: GeForce and Radeon OpenCL Test (Part 3)
- GPU Computing: GeForce and Radeon OpenCL Test (Part 4 and conclusion)
As I promised, here are the results of the OpenCL benchmarks I did with the GPU Caps Viewer 1.8.2 OpenCL demos.
Each OpenCL demo is available in two flavors: CPU and GPU. Currently the CPU version runs only on AMD platforms since AMD is the only manufacturer to provide a CPU implementation of OpenCL. In the other side, the GPU implementation of OpenCL is supported by NVIDIA and AMD.
I focuse this article on the OpenCL GPU code path.
But before diving on benchmark results, let’s have a quick look at OpenCL and the related terminology.
Overview of OpenCL
OpenCL (Open Computing Language) is an open standard for general purpose parallel programming across CPUs, GPUs and other processors like the NPU (Network Processing Unit).
OpenCL is an API and a language. The OpenCL API is used to manage OpenCL entities (compute devices, contexts, kernels, …) whereas the OpenCL language is the programming language (based on C) used to write kernels.
OpenCL offers the same functionalities than NVIDIA CUDA or Microsoft DirectCompute. All these technologies allows to use the power computation of modern GPUs, which are massively parallel, for solving general purpose problems. One nice feature of OpenCL is that OpenCL does not rely on any other APIs or technologies. You can use OpenCL alone in a simple command line application (see this news the explanation of Neil Trevett) to perform some heavy computations…
An OpenCL platform (or host) is made of one or several compute devices. A compute device is a GPU for example. Currently all GPU Caps OpenCL demos use only one OpenCL compute device. So if you have a GeForce GTX 295, only one GPU will be used. I will update later GPU Caps demos to use several compute devices to perform OpenCL computations.
Each compute device has several compute units. A compute unit is a stream multiprocessor in a GeForce GPU or a SIMD engine in a Radeon. And each compute unit has several processing elements.
A processing element is a scalar unit (or ALU or streaming processor (NV)). An OpenCL kernel is a program (coded with the OpenCL language) that is executed by all compute units in the same time.
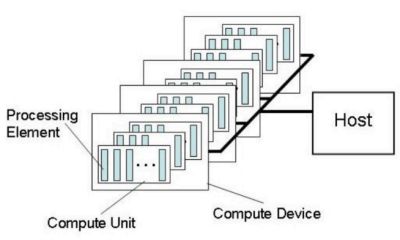
OpenCL platform model
Let’s plug some numbers to these definitions:
- GeForce GTS 250: 16 compute units. The GTS 250 has 128 scalar processors then each compute unit has 8 OpenCL processing elements (128 / 16).
- GeForce GTX 280: 30 compute units. The GTX 280 has 240 scalar processors then each compute unit has 8 OpenCL processing elements (240 / 30).
- Radeon HD 5770: 10 compute units. We know a HD 5770 has 160 vec5 processors. 160 vec5 processors are equivalent to 800 scalar processors. Each compute unit has then 80 OpenCL processing elements (800 / 10).
- Radeon HD 5870: 20 compute units. We know a HD 5870 has 320 vec5 processors. 320 vec5 processors are equivalent to 1600 scalar processors. Each compute unit has then 80 OpenCL processing elements (1600 / 20).
- Radeon HD 5670: 5 compute units (or 5 SIMD engines). From here, we know a HD 5670 has 400 stream processors: 400 / 5 = 80 OpenCL processing elements.
A compute unit of a Radeon HD 5000 series has 80 processing elements (16 processing cores with 5 ALUs per processing core) and a compute unit of a GeForce has 8 processing elements.
Programming an OpenCL application is like programming an OpenGL app, you need OpenCL headers files (few files), OpenCL.lib and OpenCL.dll. OpenCL.dll is provided by NVIDIA or AMD with their drivers. Where can you find OpenCL samples? NVIDIA, AMD and Apple have their own SDK with several samples.
To retrieve the OpenCL API support of your platform (like number of compute units or OpenCL extensions), just use the OpenCL tab of GPU Caps Viewer:

HERE you can find OpenCL details for a Radeon HD 5870 with Catalyst 9.12.
Related links:
So whats the performance numbers?
Part 2 will be available in the next minutes…
Pingback: [TEST] GPU Computing – GeForce and Radeon OpenCL Test (Part 2) - 3D Tech News, Pixel Hacking, Data Visualization and 3D Programming - Geeks3D.com
Pingback: ATI Radeon HD 5450: Direct3D 11 Capabilities for $50 - 3D Tech News, Pixel Hacking, Data Visualization and 3D Programming - Geeks3D.com
Pingback: GPU Caps Viewer 1.8.4 Available - 3D Tech News, Pixel Hacking, Data Visualization and 3D Programming - Geeks3D.com
Pingback: GF100 Fermi Die Shot + GeForce GTX 480 and GTX 470 Details - 3D Tech News, Pixel Hacking, Data Visualization and 3D Programming - Geeks3D.com
Pingback: Anonymous
Pingback: AMD Radeon HD 6870 and HD 6850: Leaked Slides Reveal New Details (Tessellation, GPU Computing) - 3D Tech News, Pixel Hacking, Data Visualization and 3D Programming - Geeks3D.com
Pingback: [Tested] ASUS ENGTX580 1536MB at Geeks3D Labs - 3D Tech News, Pixel Hacking, Data Visualization and 3D Programming - Geeks3D.com